Lsh For Finding Document Similarity
Last Tuesday winter storm Stella hit New York, and because it was impossible to commute to RC me and my roommate @nandajavarma decided to spend our afternoon coding a Python script to calculate the similarities between different documents.
Document similarity is a huge field in Natural Language Processing, so our purpose was to experiment with some simple concepts and see the results of comparing a few documents. We divided the job into two tasks to be able to cover the whole functionality in one day: my roommate was in charge of extracting the semantics of the documents while I was in charge of calculating the similarities of the resulting extractions.
Creating a semantical representation
The difference between semantical vs lexical representation lies in the idea of distance between words based on the likeness of their meaning as opposed to their lexical composition (i.e. word order, lexemes or how the String is created).
Let’s take a look at these two sentences:
- The bear shit in the woods.
- I can’t bear this shit.
Both sentences are lexically quite similar but semantically different. The word bear has a different connotation in each sentence; in the first one we can link the interpretation of ‘bear’ with ‘animal’ or ‘dangerous’ while in the second one we can link it with words like ‘handle’ or ‘upset’.

For our script we chose to extract the semantic space from the document content. The script goes through each document word by word and updates the vector representation of the document by adding its semantic relation weight value. Of course, it discards irrelevant words like prepositions or articles.
In addition of the semantic value, we also take into account the entropy of each word, grading and updating the word’s weight by its ambiguity and uninformativeness. A not very relevant word should have a high entropy, which will manifest ifself in a small update of the document vector representation.
Calculating similarities
It is possible to compare the resulting vector representation from our documents and find a semantical similarity descriptive value. I remember while writing a post a few months ago about the Jaccard Index Similarity to bump into a concept called Locality-Sensitive Hashing.
LSH is an algorithm that solves the approximate or exact Near Neighbor Search in high dimensional spaces. The general approach to LSH is to hash items multiple times, in such a way that similar items are more likely to be hashed to the same bucket than dissimilar ones.
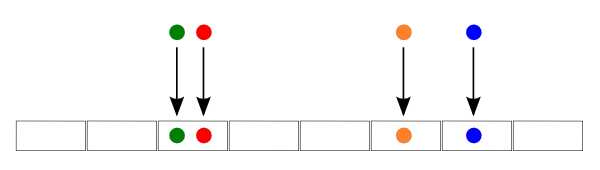
The following picture shows how four documents (represented by the colors green, red, orange and blue) are located into buckets after applied a hash function. Because the green and the red document are placed in the same bucket, we can conclude that those documents are neighbors or similar.
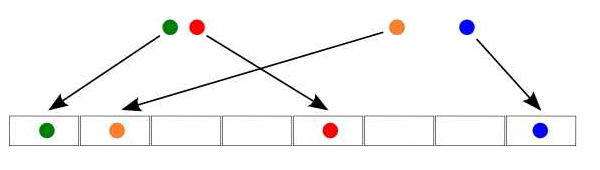
Because of the random nature of the hash function, obviously calling it only once opens the door to possible errors. In the following picture all the documents are placed in different buckets, so it is impossible for us to conclude the similarities between them.
That is why LSH hashes multiple times trying to avoid this situation.
For instance, given documents A and B our Python script get their similarity by calculating the result of N different hash functions from both document vector representations. The index similarity between both documents should be calculated by summing the number of times those hashes are placed in the same bucket and dividing that sum by the number of total hash functions - N.
Our script returns a value between zero and one representing the similarity of both documents. The closer to one the value is the more similar those documents are.
Conclusions and results
At the end, being unable to leave home because of the winter storm wasn’t that bad. It was a great experience to pair with @nandajavarma, and we managed in just one day to finish the script. Surprisingly the results when comparing different documents are quite good. We are kind of proud of what we achieved in just one afternoon.
> python similarity.py sample_pdfs/Star\ Wars.pdf sample_pdfs/Star\ Trek.pdf sample_pdfs/Chocolate.pdf
title Star Wars Star Trek Chocolate
Star Wars 1.0 0.9 0.2
In the future, it would be nice to modify the code in order to try different approaches of the LSH algorithm and compare results. For instance, it is possible to divide the vector representation of a document into N parts - instead of hashing against the whole vector, each hash function is used against one slice of the vector.